

Nog altijd komen we bedrijven tegen die moeite hebben hun voorraadstrategie af te stemmen op de vraag. Bent u ooit gevraagd een voorraad voor een hele maand aan te leggen om de verkoop veilig te stellen?
In verschillende industriële en distributiesectoren is dit beleid simpelweg gebaseerd op het verzekeren van een periodieke dekking en is het niet gedifferentieerd naar product.
De ene maand worden 10.000 verkopen van het product gerealiseerd en de volgende maand 5.000. Hoeveel is dan een maandvoorraad?
“Een maandvoorraad,” betekent natuurlijk niets. Het betekent iets achteraf, wanneer u de prestaties van uw voorraadrotaties bijhoudt, maar het is niet relevant voor het dimensioneren van uw aanvullingslussen.
Statistische formules en variabiliteitsfactoren
Al tientallen jaren worden statistische formules voorgesteld om de veiligheidsvoorraden te berekenen op basis van het verbruik in het verleden, waarbij wordt gestreefd naar een bepaald dienstverleningsniveau.
DDMRP stelt voor om voor dynamische buffers van variabiliteitsfactoren vast te stellen voor de grootte van de ‘rode veiligheidszone’.
De aanpak lijkt misschien eenvoudig, maar de ervaring leert dat voor artikelen met een grote vraagherhaling, en dus kandidaten voor ‘dynamic stock buffering’ zijn, deze variabiliteitsfactoren een veel beter antwoord geven dan veiligheidsvoorraadformules. Veiligheidsvoorraadformules leiden vaak tot hogere aantallen en zijn van nature statisch. DDMRP heeft wat gezond verstand teruggebracht in de identificatie en evaluatie van variabelen en geeft betekenis en zichtbaarheid aan deze classificatie.
Een statistische formule blijft een geschikte keuze voor artikelen met een sporadisch verbruik, hier is dus een statische buffer geschikt voor.
Hoe bepaalt u het bereik van de variabelen en de variabiliteitsfactoren die op de ‘rode zone’ moeten worden toegepast?
Variabiliteitscoëfficiënt
De meest gebruikelijke methode om artikelen in te delen op basis van de variabiliteit van de vraag, is het gebruik van de variabiliteitscoëfficiënt:
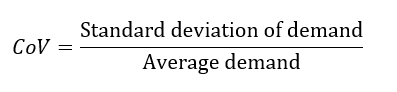
Op basis van uw artikelenportefeuille kunt u dus de variabiliteitscoëfficiënten berekenen en variabiliteitsfamilies samenstellen. Aan elke familie wordt een geschikte variabiliteitsfactor toegekend. In Intuiflow verloopt dit proces via een wizard voor voorraadbufferprofilering, waarmee u binnen een paar seconden relevante voorraadinstellingen voor duizenden artikelen kunt instellen.
Wij bevelen aan om deze CoV-berekening te baseren op dagelijkse vraagbuckets, aangezien de planners dagelijks nieuwe beslissingen moeten nemen.
Het is ook mogelijk deze CoV op week- of maandbasis te berekenen, hetgeen tot lagere waarden kan leiden. De drempels van de variabiliteitscategorieën moeten worden aangepast, maar in de meeste gevallen is er een sterke correlatie tussen de variabiliteit die op wekelijkse of dagelijkse basis wordt gemeten: de items met een lage/gemiddelde/hoge/zeer hoge variabiliteit zullen dezelfde blijven.
Zeer variabele artikelen moeten vaak nader worden onderzocht: zijn er klanten die grote eenmalige bestellingen plaatsen? Moeten pieken in de vraag buiten beschouwing worden gelaten bij de beoordeling van de variabiliteit? Moeten deze artikelen echt worden opgeslagen? Als ze echt moeten worden opgeslagen, zou een statische buffer dan geen betere optie zijn?
De grenzen van de variabiliteitscoëfficiënten
Een variabiliteitscoëfficiënt is een goede basis om categorieën van itemvariabiliteit te onderscheiden, maar geeft het vraagsignaal niet volledig juist weer.
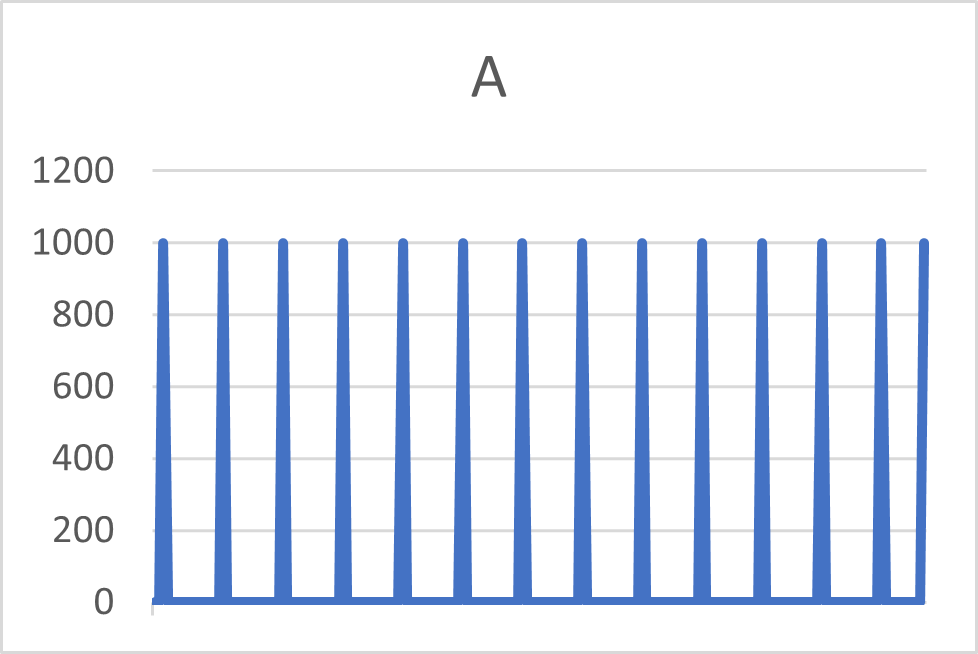
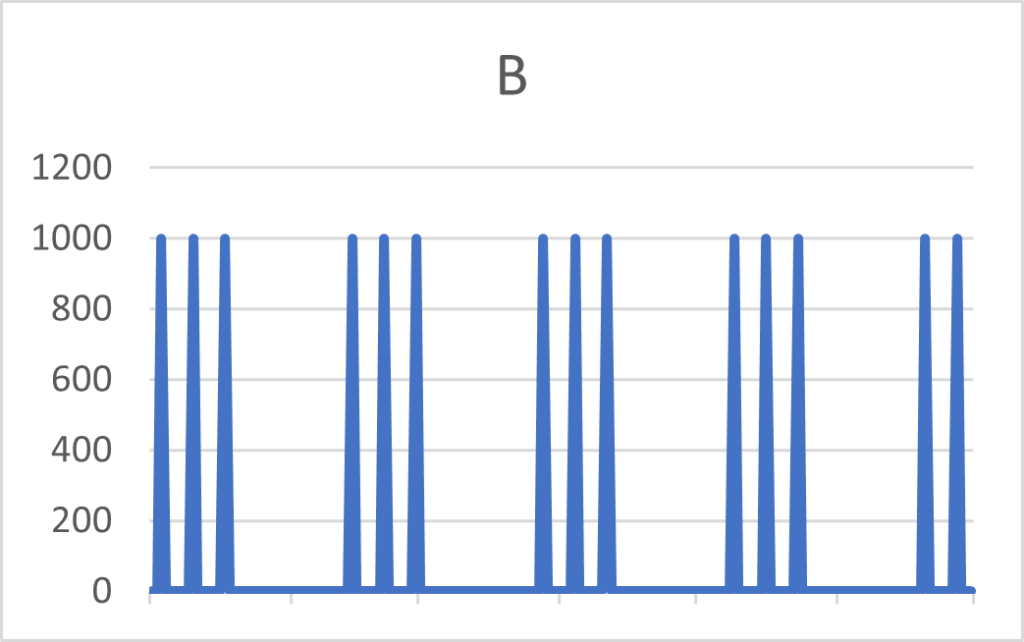
Bijvoorbeeld, de twee items A en B hieronder zullen dezelfde CoV hebben, terwijl hun vraagsignalen aanzienlijk verschillen. Afhankelijk van de aanvullingsdoorlooptijd, zal item B een hogere rode zone nodig hebben.
Kunstmatige intelligentie en clustering
Data science-technieken bieden een meer omvattende aanpak om vraagsignalen te karakteriseren. Als voorbeeld toont onderstaande grafiek (7), items die vergelijkbare vraagsignalen hebben -wat niet noodzakelijk zichtbaar is voor het menselijk oog-.
Al deze punten kunnen worden geassocieerd met het onderstaande generieke vraagsignaal:

Deze items hebben CoV-waarden tussen 50% en 150%, wat ons ertoe bracht ze in verschillende variabiliteitscategorieën in te delen, terwijl hun signalen gelijkaardig zijn.
Met behulp van kunstmatige intelligentie kunnen wij groepen items (bufferprofielen) definiëren op basis van gelijksoortige vraagpatronen en simulaties op de achtergrond uitvoeren om de parameters voor de rode zone van onze dynamische buffers te valideren. Hoe meer input-gegevens, hoe beter het resultaat.
De traditionele CoV-aanpak is vaak een aanzienlijke verbetering ten opzichte van oude manieren en heeft het voordeel eenvoudig van opzet te zijn en duidelijk leesbaar. Kunstmatige intelligentie maakt genereren op detailniveau van artikelgroeperingen mogelijk, maar het moet begrijpelijk en leesbaar blijven om ervoor te zorgen dat het voor planners betrouwbaar en werkbaar is.
Als u wilt weten hoe Intuiflow AI en Demand Driven integreert, aarzel dan niet om contact met ons op te nemen!