

Encore aujourd’hui on rencontre des entreprises qui ont du mal à différencier leurs stratégies de stockage en fonction des profils de demande. Avez-vous déjà entendu des injonctions du type « Mettez-moi un mois de stock pour sécuriser nos ventes» ?
Dans plusieurs secteurs industriels ou de distribution on trouve effectivement cette politique, basée sur un nombre de jours de couverture, indifférenciée en fonction des produits.
Un mois vous pouvez vendre 10 000 et le mois suivant 5 000. Ca fait combien un mois de stock ?
« Un mois de stock », bien entendu, ça ne veut rien dire. Ça veut dire quelque chose après coup, quand vous suivez l’évolution de votre performance de rotation de stock – mais ce n’est pas pertinent pour dimensionner vos consignes de réapprovisionnement.
Formules statistiques et facteurs de variabilité
Depuis des décennies plusieurs formules statistiques ont été proposées pour dimensionner des stocks de sécurité sur la base des historiques de consommation, en visant un taux de service donné.
DDMRP propose, pour les buffers dynamiques, d’établir des facteurs de variabilité pour dimensionner la zone rouge de sécurité.
L’approche peut paraître basique, mais l’expérience montre que pour des articles présentant une bonne récurrence de demande, et donc candidats à buffer de stock dynamique, ces facteurs de variabilité apportent une bien meilleure réponse que les formules de stock de sécurité. Les formules de stock de sécurité conduisent souvent à des niveaux plus élevés, et sont par nature statiques. DDMRP a remis du bon sens dans l’identification et l’évaluation des variabilités, et donne du sens et de la visibilité à cette classification.
Une formule statistique reste un choix opportun pour des articles à consommation sporadique, pour lesquels un buffer statique est approprié.
Comment définir les plages de variabilité et les facteurs de variabilité à appliquer à la zone rouge ?
Coefficient de variabilité
La méthode la plus courante pour classifier les articles en fonction de la variabilité de la demande est d’utiliser le coefficient de variabilité :

En fonction de votre portefeuille d’articles vous pouvez donc calculer les coefficients de variabilité, et établir des familles de variabilité. Pour chaque famille de variabilité on affecte un facteur de variabilité adapté. Dans Intuiflow ce processus est réalisé par un assistant de profilage de buffers de stock, qui permet en quelques secondes de paramétrer des paramétrages de stock pertinents pour des milliers d’articles.
Nous recommandons que ce calcul de CoV soit fait sur une base de demande quotidienne, car c’est à la journée, au vu de la demande d’aujourd’hui, que nos planificateurs doivent prendre des décisions.
Il est aussi possible de calculer ce CoV à la semaine ou au mois ce qui conduit à des valeurs plus faibles. Les seuils de catégories de variabilité sont à adapter, mais dans la majorité des cas il y a une forte corrélation entre variabilité mesurée à la semaine ou au jour : les articles à faible / moyenne / forte / très forte variabilité resteront les mêmes.
Les articles à très forte variabilité sont souvent à examiner de plus près : est-ce qu’il y a des clients qui passent des commandes importantes ponctuelles ? Est-ce que ces articles sont vraiment à stocker ? S’ils sont vraiment à stocker, est-ce qu’un buffer statique ne serait pas une meilleure option ?
Les limites des coefficients de variabilité
Un coefficient de variabilité est une bonne base pour différencier les catégories de variabilité des articles, mais ça ne caractérise pas pleinement le signal de demande.
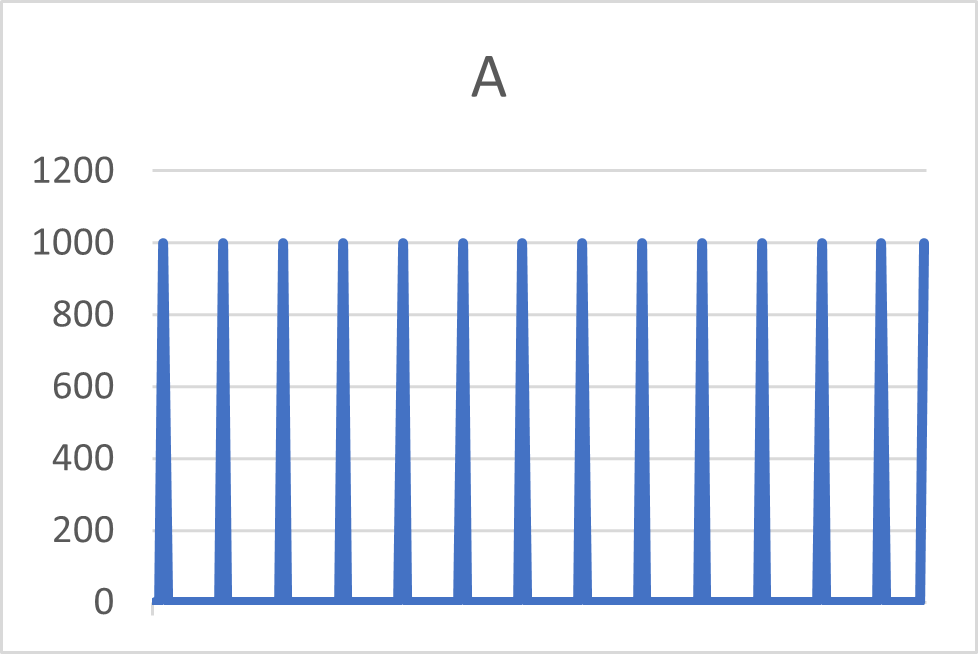
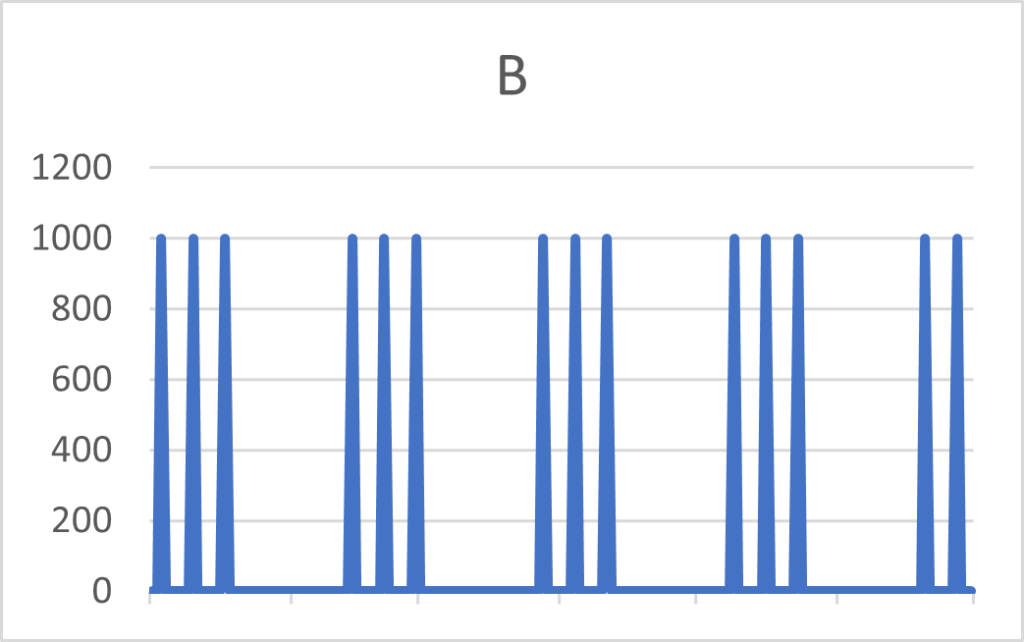
Par exemple les deux articles A et B ci-dessous vont avoir le même CoV, alors que leurs signaux de demande sont significativement différents. En fonction du délai de réappro l’article B aura besoin d’une zone rouge plus élevée.
Intelligence artificielle et clustering
Les techniques de data science apportent une approche plus complète pour caractériser les signaux de demande. A titre d’exemple, le graphe ci-dessous montre 7 articles qui ont des signaux de demande similaire – ce qui n’est pas nécessairement évident pour l’œil humain…


Ces articles ont en l’occurrence des valeurs de CoV comprises entre 50% et 150%, ce qui nous aurait amené à les classifier dans des profils différents, alors que leurs signaux sont similaires.
Par l’approche d’intelligence artificielle il nous est donc possible de définir des groupes d’articles (profils de buffer) regroupés par similitude des signaux de demande, et de faire tourner en tâche de fond des simulations pour valider les paramètres de zone rouge de nos buffers dynamiques. Plus il y a de données qui alimentent l’apprentissage du moteur de machine learning, meilleur est le résultat.
L’approche traditionnelle de CoV est souvent un progrès important par rapport à l’existant, et elle présente l’avantage de la simplicité et de la lisibilité. L’intelligence artificielle permet de générer avec plus de finesse des regroupements d’articles, mais doit rester compréhensible et lisible pour assurer que les planificateurs puissent lui faire confiance.
Si vous voulez savoir comment Intuiflow intègre IA et Demand Driven, ne pas hésiter à nous contacter !…








